

Service Géoplateforme de recherche
- 1. Généralités
- 2. Usage
- 2.1 Recherche standard
- 2.1.1 Recherche dans les index – POST - /api/indexes/{index}
- 2.1.2 Récupération des capabilities des index – GET - /api/indexes/
- 2.1.3 Autocomplétion de titres – GET - /api/indexes/{index}/suggest_autocomplete
- 2.1.4 Suggestion par champ(s) – GET - /api/indexes/{index}/suggest
- 2.1.5 Consultation d’un document par ID – GET - /api/indexes/{index}/documents/{documentID}
- 2.1.6 Consultation d’un document par offres– GET - /api/indexes/{index}/documents/offerings/{offeringId}
- 2.2 Recherche custom
- 2.2.1 Créer et publier un index custom
- 2.2.2 Mettre à jour un index custom
- 2.2.3 Effectuer une recherche dans un index custom
- 3. Documentation swagger
- 4. Bascule du service recherche de la GPF
Table des matières
Titre
1. Généralités
Description globale
La Géoplateforme propose un service de recherche, qui permet d’effectuer des recherches sur les données. Ses recherches peuvent fonctionner avec plusieurs options (recherche approximative, autocomplétion, etc).
Il est limité à 10 requêtes/s.
Ce service est scindé en deux fonctionnements :
- une recherche standard qui s’effectue sur les données publiées dans l’entrepôt de la Géoplateforme
- une recherche custom qui fonctionne sur des données importées
Recherche standard
Le service de recherche standard s’effectue sur l’index dit général de la Géoplateforme. Il permet d’obtenir des informations pour tout type d’offre entreposée de base dans la Géoplateforme. Toutes les données des grands producteurs (IGN, CEREMA, SHOM, MNHN, etc) pourront être recherchées à travers les services suivants :
- Les données du Service d'images tuilées WMTS
- Les données du Service de tuiles vectorielles TMS
- Les données du Service d'images WMS-Raster
- Les données Service d'images WMS-Vecteur
- Les données du Service de sélection WFS
- Les données du service de calcul d’itinéraires
- Les données du service de calcul d’isochrone/isodistance
- Les données du service d’altimétrie
Les éléments de recherche sur ces données sont synchronisés au moment de la publication (ou dépublication) des offres. On considère que ces documents de recherche font partie de l'index « geoplateforme ».
Recherche custom
En plus de l'index standard, il est possible de créer ses propres index de recherche : ce sont les index custom. Ces index regroupent toutes les offres qui n’existent pas dans l’entrepôt de base de la Géoplateforme, mais qui ont été importées et publiées par des producteurs extérieurs. La recherche ne s’effectuant plus sur l'index « geoplateforme » mais sur l'index custom.
Par exemple, la liste des arrêts de bus de Madrid (Espagne) ne semble pas être une offre disponible depuis l’entrepôt de base de la Géoplateforme. Cependant un producteur extérieur peut importer un fichier CSV ou JSON de la liste des arrêts de bus de Madrid. Cette liste permet de créer un index custom. Une recherche peut alors être réalisée, non plus seulement sur l'index général de la Géoplateforme, mais aussi sur l'index custom des arrêts de bus de Madrid.
Consultation des index
L’index standard « geoplateforme » est accessible sans droits particuliers, directement via un URL (disponible à la partie suivante).
Pour consulter un index custom, il faut :
- soit obtenir l’accès à partir d’une clé créée par le producteur de l’index custom
- soit être connecté à l’API Entrepôt. Des tutoriels et une documentation de l’API Entrepôt sont disponibles.
Connexion au service de recherche
Les deux fonctionnements du service de recherche sont accessibles via le protocole API REST.
Ils sont accessibles aux adresses suivantes :
| Service | URL d'accès |
|---|---|
| GetCapabilities de recherche standard | https://data.geopf.fr/recherche/api/indexes |
| GetCapabilities de recherche custom | https://data.geopf.fr/private/recherche/api/indexes |
Pour obtenir une description détaillée du service, veuillez-vous référer à la section Usage.
Titre
2. Usage
Cette partie a pour but d’expliquer les utilisations et fonctionnements du service de recherche. Il s’articule en 3 parties :
- la recherche standard : comment l’effectuer, avec une description de chaque requête
- la recherche custom : comment créer un index custom et effectuer une recherche dans cet index custom
- la documentation swagger : elle reprend dans l’interface swagger les grands principes de l’API et ses requêtes (décrites dans la partie « recherche standard ») et permet d’effectuer des tests directement
Cette documentation a vocation de s’adresser à un utilisateur occasionnel. Selon votre profil, une documentation orientée producteur de données/développement est disponible ainsi qu’un swagger.
Titre
2.1 Recherche standard
Une recherche standard s’effectue sur les données publiées de base dans l’entrepôt de la Géoplateforme.
Les informations pour la recherche sont générées automatiquement à partir des offres de base de la Géoplateforme.
Cette partie décrit le fonctionnement de chaque requête liée aux recherches standards (ci-dessous)
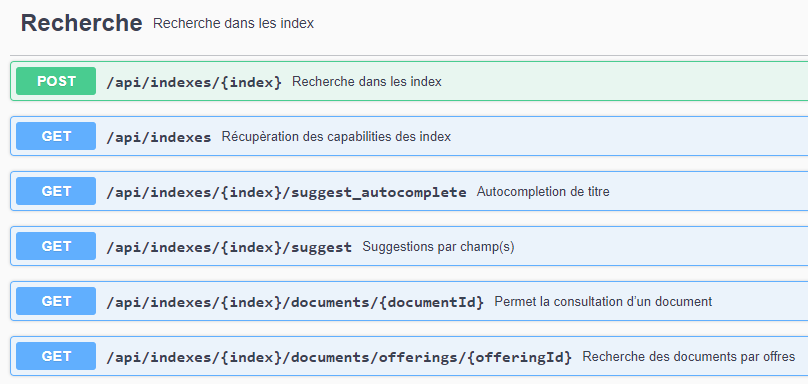
Titre
2.1.1 Recherche dans les index – POST - /api/indexes/{index}
C’est la requête de recherche de base. Elle permet de rechercher dans les index dans la Géoplateforme.
Paramètres obligatoires/optionnels et contraintes
| Paramètre | Description | Type/format | Requis | Valeurs possibles | Valeur par défaut | Contraintes |
|---|---|---|---|---|---|---|
| index | identifiant de l’index | texte | oui | |||
| page | numéro de la page, commence à 1 | entier | non | 1 | ||
| size | nombre maximum de résultats par page | entier | non | 10 | ||
Comme nous sommes dans une requête POST, la requête doit être accompagnée d’un objet JSON qu’on appelle body et qui définit des paramètres.
Il est possible de rechercher à partir de nombreux champs dans les documents de recherche, aucun des champs n’étant obligatoire pour effectuer la recherche. Néanmoins, si aucun champ n'est précisé dans le body JSON, la réponse obtenue renvoie tous les documents présents dans l'index « geoplateforme ».
Exemple d'appel
https://data.geopf.fr/recherche/api/indexes/geoplateforme?page=1&size=10
Body
{
title : "Titre",
layer_name : "layer_name",
description : "Description",
open : true,
highlight : true,
type : "WMS",
theme : "Thématique",
keywords : "Mots clefs associés",
srs : "EPSG:4326",
shape :
{
"type": "MultiPoint",
"coordinates": [ [ 68.0, 44.0 ], [ 78.0, 28.0 ] ]
}
publication_date :
{
"min_publication_date" : "2023-05-15",
"max_publication_date" : "2023-12-01"
},
production_year :
{
"min" : 1920,
"max" : 1922
},
aggregation :
{
"fields": ["type"]
}
}
Résultat
Résultat
{
"documents": [
{
"id": "4c2afe00-d2a4-4536-a254-e4025aa8daf7",
"offering_id": "c39d62ca-f696-4f60-98a5-9b4e02a6b5c6",
"index_name": "geoplateforme",
"layer_name": "bdtopo_971:non_communication",
"title": "Routes de non communication 971",
"description": "Routes de non communication du département 971",
"type": "WFS",
"url": "https://data.geopf.fr /wfs?service=WFS&version=2.0.0&request=DescribeFeatureType&typeNames=bdtopo_971:non_communication",
"open": true,
"theme": "BD_topo",
"production_year": 2023,
"publication_date": "2023-09-18",
"keywords": [
"BD_Topo",
"Routes"
],
"extent": {
"type": "Polygon",
"coordinates": [
[
[
180,
-90
],
[
180,
90
],
[
-180,
90
],
[
-180,
-90
],
[
180,
-90
]
]
]
},
"metadata_urls": [],
"srs": [
"EPSG:5490"
],
"highlights": {}
},
{
"id": "ccbb7c1d-4031-4387-a1aa-bd72e209faf4",
"offering_id": "c39d62ca-f696-4f60-98a5-9b4e02a6b5c6",
"index_name": "geoplateforme",
"layer_name": "bdtopo_971:troncon_de_route",
"title": "Tronçons de route 971",
"description": "Tronçons de route du département 971",
"type": "WFS",
"url": "https://data.geopf.fr /wfs?service=WFS&version=2.0.0&request=DescribeFeatureType&typeNames=bdtopo_971:troncon_de_route",
"open": true,
"theme": "BD_topo",
"production_year": 2023,
"publication_date": "2023-09-18",
"keywords": [
"BD-Topo",
"Routes"
],
"extent": {
"type": "Polygon",
"coordinates": [
[
[
180,
-90
],
[
180,
90
],
[
-180,
90
],
[
-180,
-90
],
[
180,
-90
]
]
]
},
"metadata_urls": [],
"srs": [
"EPSG:5490"
],
"highlights": {}
}
],
"aggregations": {}
}
Explications
Ce que l’on a appelé correspond à :
{url}/api/indexes/{index}
- {url} est ici « https://data.geopf.fr/recherche»
- {index} est ici « geoplateforme ». « geoplateforme » correspond au nom de l’index standard de toutes les offres de la Géoplateforme. Le nom de l’index est un paramètre obligatoire dès que l’on veut réaliser une recherche.
La requête prend ici 2 paramètres de recherche (« ? » à la suite de la requête). On a spécifié que l’on ne voulait que les résultats de recherche de la page numéro 1 (« page=1 ») et (« & ») que l’on voulait afficher maximum 10 pages de résultats (« size=10 »). Ces paramètres ne sont pas obligatoires, mais les valeurs décrites dans cet exemple correspondent à des paramètres par défaut.
Body :
Normalement le body n’est pas aussi chargé que celui de l’exemple. En temps normal, une requête est envoyée avec seulement 1 ou 2 paramètres. Cet exemple nous permet de décrire au mieux les spécifications possibles dans la requête de recherche
title : "Titre",
correspond au titre de la ressource
layer_name : "layer_name",
correspond au nom technique de la ressource
description : "Description",
correspond à la description de la ressource recherchée
open : true,
correspond à la visibilité attendue de l'offre (renvoi à une balise liée à l’API Entrepôt)
- true : si la donnée est présente dans le catalogue de la Géoplateforme
- false : si la donnée n’est pas présente dans le catalogue
highlight : true,
permet de surligner les éléments qui correspondent à celui recherché (voir parties suivantes pour des explications)
type : "WMS",
correspond au type d'offre :
- WFS
- WMS-RASTER
- WMS-VECTOR
- WMTS-TMS
- DOWNLOAD
- ITINERARY ISOCURVE
- ALTIMETRY
theme : "Thématique",
correspond à la thématique de la ressource. La thématique est spécifiée par le producteur de la donnée.
keywords : "Mots clefs associés",
correspond aux mots clés associés à la ressource. Les mots clés sont spécifiés par le producteur de la donnée.
srs : "EPSG:4326",
définit la projection de la ressource
shape : { "type": "MultiPoint", "coordinates": [ [ 68.0, 44.0 ], [ 78.0, 28.0 ] ]},
définit l’emprise géographique de la recherche. Ici l’emprise est définie par plusieurs points.
publication_date : {"min_publication_date" : "2023-05-15", "max_publication_date" : "2023-12-01"},
définit des dates de publication de la donnée au sein desquelles on veut effectuer la recherche. Le format de la date est obligatoirement « AAAA-MM-JJ ».
production_year : { "min" : 1920, "max" : 1922 },
définit des dates de production de la donnée au sein desquelles on veut effectuer la recherche
aggregation : {"fields": ["theme"]}
permet d’effectuer une agrégation sur un champ des documents de recherche (voir parties suivantes pour des explications)
Highlight
Le highlight (ou surligneur en français) permet de mettre en relief ou surbrillance les éléments qui correspondent à celui recherché.
Dans une barre de recherche, cela permet de voir les matchs potentiels dans une petite liste de résultats possibles au fur et à mesure que l’on écrit.
Dans l’API de recherche, cela se traduit par un champ mis en surbrillance dans la réponse. Le texte HTML issu du document est déjà mis en relief.
Aggregation
Lors de la recherche, le système d'agrégation permet de donner des informations sur les regroupements potentiels des documents qui pourraient correspondre.
Par exemple ici, nous avons demandé une recherche sur le champ correspondant à la thématique ( {"fields": ["theme"]} ). Si notre recherche se base sur les années de production de 1920 à 1922 et que nous demandons une agrégation sur le thème, on pourrait avoir en résultat 100 documents qui ont tous pour thème "Paris", et 500 autres tous pour thème "Lyon". Cela nous donne plus d'informations sur notre recherche et nous permet potentiellement de l’affiner.
L'agrégation par emprise spatiale est pour le moment indisponible. Seuls les champs de type chaine de caractères (texte) sont disponibles.
Titre
2.1.2 Récupération des capabilities des index – GET - /api/indexes/
Cette requête permet de lister les index disponibles et de récupérer leurs paramètres.
Paramètres obligatoires/optionnels et contraintes
| Paramètre | Description | Type/format | Requis | Valeurs possibles | Valeur par défaut | Contraintes |
|---|---|---|---|---|---|---|
| page | numéro de la page, commence à 1 | entier | non | 1 | ||
| size | nombre maximum de résultats par page | entier | non | 10 | ||
Exemple d'appel
https://data.geopf.fr/recherche/api/indexes?page=1&size=1
Rsultat
[
{
"title": "Standard index",
"index": "geoplateforme",
"keywords": [],
"url": "https://data.geopf.fr/api/indexes/geoplateforme",
"configuration_json": {
"properties": {
"attribution": {
"properties": {
"logo": {
"properties": {
"format": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"height": {
"type": "long"
},
"url": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"width": {
"type": "long"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"titleSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"email": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"emailSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"url": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"descriptionSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"endpointUrl": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"extent": {
"type": "geo_shape"
},
"indexName": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"keywords": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"keywordsSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"layerName": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"layerNameSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"licence": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"metadataUrls": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"offeringId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"open": {
"type": "boolean"
},
"productionYear": {
"type": "long"
},
"publicationDate": {
"type": "date"
},
"theme": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"themeSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"thumbnail": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"titleSuggest": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "suggest_analyzer"
},
"type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"abstract": "Standard index"
}
]
Titre
2.1.3 Autocomplétion de titres – GET - /api/indexes/{index}/suggest_autocomplete
Cette requête permet l’autocomplétion du titre dans la recherche. Elle permet de corriger les mots d'une recherche pour correspondre aux mots des champs du document. L'autocomplétion de titre est utilisable sur les champs suivant : title, description, theme et keywords.
Sans précision du champ précisé, l'autocomplétion a lieu sur le champ title.
Paramètres obligatoires/optionnels et contraintes
| Paramètre | Description | Type/format | Requis | Valeurs possibles | Valeur par défaut | Contraintes |
|---|---|---|---|---|---|---|
| index | identifiant de l’index | texte | oui | |||
| text | texte à rechercher | texte | oui | |||
| field | champ sur lequel va s’effectuer l’autocomplétion | texte | non | title, description, theme, keywords | title | |
Exemple d'appel
https:// data.geopf.fr/recherche/api/indexes/geoplateforme/suggest_autocomplete?text=rout%20de%20communiation&field=title
Résultat
[
{
"text": "communiation",
"offset": 8,
"length": 12,
"options": [
{
"text": "communication",
"score": 0.9166667,
"freq": 1
},
{
"text": "communications",
"score": 0.8333333,
"freq": 2
}
]
},
{
"text": "de",
"offset": 5,
"length": 2,
"options": []
},
{
"text": "rout",
"offset": 0,
"length": 4,
"options": [
{
"text": "routes",
"score": 0.5,
"freq": 1
},
{
"text": "route",
"score": 0.75,
"freq": 19
}
]
}
]
Titre
2.1.4 Suggestion par champ(s) – GET - /api/indexes/{index}/suggest
Cette requête permet la suggestion pour un ou plusieurs champs. La suggestion par champ permet une autocomplétion (sur les champs autorisés) du texte recherché suivant le champ demandé. La suggestion commence à partir de l'écriture de 3 lettres.
Les champs utilisables pour la suggestion sont title, description, layer_name, theme et keywords. La requête s’effectue de base sur tous ces champs en même temps. Pour l’effectuer sur un seul champ, le paramètre « fields » doit être définit.
Remarque : Cette requête ne fonctionne pas avec un index custom, même si celui-ci est balisé « is_search_layer=true ».
Paramètres obligatoires/optionnels et contraintes
| Paramètre | Description | Type/format | Requis | Valeurs possibles | Valeur par défaut | Contraintes |
|---|---|---|---|---|---|---|
| index | identifiant de l’index | texte | oui | |||
| text | texte à rechercher | texte | oui | |||
| fields | Liste des champs de recherche | Array[string] | non | title, description, theme, keywords, layer_name | ||
| size | Nombre d’éléments à récupérer | Entier ($int32) | non | 10 | ||
Exemple d'appel
https:// data.geopf.fr/recherche/api/indexes/geoplateforme/suggest?text=bd%20topo&fields=keywords&size=1
Résultat
[
{
"index": "geoplateforme",
"score": 3.4832718,
"source": {
"id": "fc2af911-d9c2-4fc8-aee7-46034eebf821",
"offering_id": "faa4c69c-d03b-4502-af87-7f3667411321",
"index_name": "geoplateforme",
"layer_name": "nl_bdtopo_allauch",
"title": "NL - BD Topo : Allauch",
"description": "Extrait de BD TOPo sur Allauch",
"type": "WMS",
"url": "https://data.geopf.fr/wms-v?service=WMS&version=1.3.0&request=GetMap&layers=nl_bdtopo_allauch&bbox={xmin},{ymin},{xmax},{ymax}&styles={styles}&width={width}&height={height}&srs={srs}&format={format}",
"open": true,
"publication_date": "2023-11-27",
"keywords": [
"BDTOPO",
"Recette"
],
"extent": {
"type": "Polygon",
"coordinates": [
[
[
5.60100167,
43.29462375
],
[
5.60100167,
43.40984679
],
[
5.42013549,
43.40984679
],
[
5.42013549,
43.29462375
],
[
5.60100167,
43.29462375
]
]
]
},
"metadata_urls": [],
"srs": [
"EPSG:2154"
]
}
}
]
Titre
2.1.5 Consultation d’un document par ID – GET - /api/indexes/{index}/documents/{documentID}
Cette requête permet de retrouver un document en fonction de son ID. Elle est utile si l’ID du document est déjà connu ou alors si une application cliente l’a préalablement récupéré.
Remarque : Cette requête ne fonctionne pas avec un index custom, même si celui-ci est balisé « is_search_layer=true ».
Paramètres obligatoires/optionnels et contraintes
| Paramètre | Description | Type/format | Requis | Valeurs possibles | Valeur par défaut | Contraintes |
|---|---|---|---|---|---|---|
| index | identifiant de l’index | texte | oui | |||
| documentId | identifiant du document demandé par la requête | texte ($uuid) | oui | |||
Exemple d'appel
https://data.geopf.fr/recherche/api/indexes/geoplateforme/documents/4c2afe00-d2a4-4536-a254-e4025aa8daf7
Résultat
{
"id": "4c2afe00-d2a4-4536-a254-e4025aa8daf7",
"offering_id": "c39d62ca-f696-4f60-98a5-9b4e02a6b5c6",
"index_name": "geoplateforme",
"layer_name": "bdtopo_971:non_communication",
"title": "Routes de non communication 971",
"description": "Routes de non communication du département 971",
"type": "WFS",
"url": "https:// data.geopf.fr/wfs?service=WFS&version=2.0.0&request=DescribeFeatureType&typeNames=bdtopo_971:non_communication",
"open": true,
"theme": "BD_topo",
"production_year": 2023,
"publication_date": "2023-09-18",
"keywords": [
"BD_Topo",
"Routes"
],
"extent": {
"type": "Polygon",
"coordinates": [
[
[
180,
-90
],
[
180,
90
],
[
-180,
90
],
[
-180,
-90
],
[
180,
-90
]
]
]
},
"metadata_urls": [],
"srs": [
"EPSG:5490"
]
}
Titre
2.1.6 Consultation d’un document par offres– GET - /api/indexes/{index}/documents/offerings/{offeringId}
Cette requête permet la consultation d’un document en fonction de l’ID de son offre. Cela permet de récupérer tous les IDs de documents issus d'une offre. Une recherche par l’ID du document (ci-dessus) peut ensuite être effectuée.
Remarque : Cette requête ne fonctionne pas avec un index custom, même si celui-ci est balisé « is_search_layer=true ».
Paramètres obligatoires/optionnels et contraintes
| Paramètre | Description | Type/format | Requis | Valeurs possibles | Valeur par défaut | Contraintes |
|---|---|---|---|---|---|---|
| index | identifiant de l’index | texte | oui | |||
| offeringId | identifiant de l’offre | texte ($uuid) | oui | |||
Exemple d'appel
https://data.geopf.fr/recherche/api/indexes/geoplateforme/documents/offerings/c39d62ca-f696-4f60-98a5-9b4e02a6b5c6
Résultat
[
{
"id": "7bc8c9a9-5f11-4ab9-bbde-2d941d0cb0fe"
},
{
"id": "3407960f-52e0-44a8-bb51-ba5615b8ee1f"
}
]
Titre
2.2 Recherche custom
Une recherche custom fonctionne sur des index importés, qu’on appelle alors index custom. Pour créer un index custom, les données doivent préalablement être déposées sur la Géoplateforme.
Le contenu des données est libre, mais un formalisme est imposé.
Titre
2.2.1 Créer et publier un index custom
Format des données sources
Les formats CVS et JSON sont acceptés pour le dépôt. Au sein d'une livraison, ils doivent tous contenir les mêmes types de données et le même nombre de colonnes. Les colonnes doivent contenir des éléments alphanumériques (a-z, 1-9 et _). Les types disponibles sont : string, date et geoJSON ou WKT.
Un fichier doit être déposé avec un fichier affilié qui décrit son schéma. Ce fichier de schéma doit porter le même nom que le fichier de données. Chaque fichier CSV doit être accompagné d’un fichier du même nom au format CSVT. Chaque fichier JSON doit être accompagné d'un fichier schema.json.
Format CSV
Le séparateur pour le CSV doit être un point-virgule : « ; ».
Exemple de fichier CSVT utilisant une géométrie WKT :
String;String;Date;WKT
Ici nous déclarons que le fichier contiendra 4 colonnes : les 2 premières de type String (champs libres), le 3eme de type Date et le dernier de type WKT.
Exemple de fichier CSV correspondant :
name;description;date;geometry
Example Name;Example Description;08/01/2009;POINT(8.8249 47.2274)
Place Mayor;Une place historique au cœur de Madrid, réputée pour son architecture magnifique et son ambiance animée.;09/01/2009;POINT(-3.7079 40.4154)
La première ligne du fichier CSV contient le nom des colonnes. Il contient ensuite des informations sur deux points. La dernière colonne porte les coordonnées du lieu est au format WKT.
Exemple de fichier CSVT utilisant une géométrie geoJSON :
String;String;Date; CoordX;CoordY
Ici nous déclarons que le fichier contiendra 4 colonnes : les 2 premières de type String (champs libres), le 3eme de type Date et les deux derniers de type geoJSON.
Exemple de fichier CSV correspondant :
name;description;date;geometry
Example Name;Example Description;08/01/2009;8.8249 ;47.2274
Place Mayor;Une place historique au cœur de Madrid, réputée pour son architecture magnifique et son ambiance animée.;09/01/2009;POINT(-3.7079 40.4154)
La première ligne du fichier CSV contient le nom des colonnes. Il contient ensuite des informations sur deux points. La dernière colonne porte les coordonnées du lieu est au format geoJSON.
Format JSON
Exemple de fichier SCHEMA JSON utilisant une géométrie WKT :
{
"type": "array",
"items" : {
"type": "object",
"properties": {
"name": {"type": "string"},
"date": {"type": "string", format: "date"},
"geometry": {"type": "WKT"}
}
}
}
Ce schéma JSON définit un objet avec trois propriétés : "name", "date" et "geometry". Chaque propriété a un type de valeur spécifié : "name" est de type string, « date » porte deux types string et date, geometry est de type WKT.
Exemple de fichier JSON correspondant :
[
{
"name": "Example Object",
"date": "2023-05-15",
"geometry": "POINT(8.8249 47.2274)"
}
]
Ce fichier JSON respecte la structure du schéma.
Exemple de fichier SCHEMA JSON utilisant une geoJSON de type Point :
{
"type": "array",
"items" : {
"type": "object",
"properties": {
"name": {"type": "string"},
"date": {"type": "string", format: "date"},
"geometry": {
"type": "object",
"properties" : {
"type" : {
"type" : "string",
"enum" : ["Point"]
},
"coordinates" :{
"type" : "array",
"minItems : 2
"items" : {
"type" : "number"
}
}
}
}
}
}
}
Exemple de fichier JSON correspondant :
[
{
"titre" : "Titre1",
"date" : "2023-05-15",
"geometry" : {"type" : "Point" , "coordinates" : [100.0, 0.0]}
}
]
Ce fichier JSON respecte la structure du schéma.
Particularité du Search Layer
Il y a deux fonctionnements à une recherche custom, qui dépendent du schéma des données importées et de la balise « is_search_layer ».
Si l‘index custom a un schéma compatible Search Layer et porte un paramètre « is_search_layer :true », alors la recherche s’effectue sur les mêmes paramètres qu’une recherche standard.
Si l’index custom n’a pas un schéma compatible Search Layer et porte le paramètre « is_search_layer :false », alors les champs sur lesquels s’effectue la recherche sont ceux uniquement définis dans le schéma importé en parallèle du fichier de données. Certaines fonctionnalités de la recherche standard ne se retrouvent pas dans la recherche custom (suggestion par champs, consultation par ID ou offre).
Si une livraison qui a pour but de créer un index custom souhaite être recherché comme un index standard, elle doit respecter le formalisme décrit ci-dessous et baliser « is_search_layer :true » dans l’étape : Upload dans la Géoplateforme.
Search_layer pour les CSV
Le fichier CSVT doit contenir obligatoirement le format suivant :
UUID;String;String;String;Boolean;String;String;String;String;String;String;String;String;String;String;String;WKT;String;Date;Array;String;Array;Array
Le fichier CSV doit correspondre exactement au fichier CSVT.
Exemple de fichier CSV compatible Search Layer :
offeringId;layerName;title;description;open;thumbnail;type;endpointUrl;attribution_title;attribution_url;attribution_email;attribution_logo_format;attribution_logo_url;attribution_logo_width;attribution_logo_height;productionYear;extent;theme;publicationDate;keywords;licence;metadataUrls;srs
00112233-4455-6677-8899-aabbccddeeff;Example Layer;Example Title;This is an example description;true;https://example.com/thumbnail.jpg;WFS;https://example.com/endpoint;Example Attribution;https://example.com/attribution;contact@example.com;png;https://example.com/logo.png;100;50;2023;POINT(24.0212 5.0565);Example Theme;2023-08-03;["example"];Example License;["https://example.com/metadata1"];["EPSG:4326"]
S'il y a plusieurs fichiers, le schéma établi par le CSVT doit être respecté.
Search_layer pour les JSON
Le SCHEMA JSON doit contenir obligatoirement le format suivant :
{
"type": "array",
"items" : {
"type":"object",
"properties":{
"offeringId":{
"type":"string",
"format":"uuid"
},
"layerName":{
"type":"string"
},
"title":{
"type":"string"
},
"description":{
"type":"string"
},
"open":{
"type":"boolean"
},
"thumbnail":{
"type":"string"
},
"type":{
"type":"string"
},
"endpointUrl":{
"type":"string",
"format":"uri"
},
"attribution":{
"type":"object",
"properties":{
"title":{
"type":"string"
},
"url":{
"type":"string",
"format":"uri"
},
"email":{
"type":"string",
"format":"email"
},
"logo":{
"type":"object",
"properties":{
"format":{
"type":"string"
},
"url":{
"type":"string",
"format":"uri"
},
"width":{
"type":"integer",
"minimum":1
},
"height":{
"type":"integer",
"minimum":1
}
}
}
}
},
"productionYear":{
"type":"integer"
},
"extent":{
"type":"object"
},
"theme":{
"type":"string"
},
"publicationDate":{
"type":"string",
"format":"date"
},
"keywords":{
"type":"array",
"items":{
"type":"string"
}
},
"licence":{
"type":"string"
},
"metadataUrls":{
"type":"array",
"items":{
"type":"string",
"format":"uri"
}
},
"srs":{
"type":"array",
"items":{
"type":"string"
}
}
}
}
}
Les fichiers JSON doivent correspondre exactement au schéma du fichier SCHEMA JSON.
Exemple de fichier JSON compatible au Search Layer (le nom des colonnes n'est pas modifiable) :
[
{
"offeringId":"00112233-4455-6677-8899-aabbccddeeff",
"layerName":"Example Layer",
"title":"Example Title",
"description":"This is an example description.",
"open":true,
"thumbnail":"https://example.com/thumbnail.jpg",
"type":"example",
"endpointUrl":"https://example.com/endpoint",
"attribution":{
"title":"Example Attribution",
"url":"https://example.com/attribution",
"email":"contact@example.com",
"logo":{
"format":"png",
"url":"https://example.com/logo.png",
"width":100,
"height":50
}
},
"productionYear":2023,
"extent":{
"north":40.0,
"south":30.0,
"east":-80.0,
"west":-90.0
},
"theme":"Example Theme",
"publicationDate":"2023-08-03",
"keywords":[
"example",
"data",
"json",
"schema"
],
"licence":"Example License",
"metadataUrls":[
"https://example.com/metadata1",
"https://example.com/metadata2"
],
"srs":[
"EPSG:4326",
"EPSG:3857"
]
}
]
Livraison des fichiers
Pour créer ces index custom, la première étape est de livrer les fichiers dans l'entrepôt. La publication des index custom est identique à la publication d’autres offres. Cela crée une offre de type INDEX.
Upload dans la Géoplateforme
Pour publier un index, il doit être chargé (ou uploadé) sur la Géoplateforme. Il faut commencer par créer la livraison. Pour cela on utilise l’API Entrepôt de la Géoplateforme. Des tutoriels et une documentation de l’API Entrepôt sont disponibles.
Une fois connecté, vous devrez vous assurer que le datastore possède la vérification checkindex, le storage OPENSEARCH, le traitement index2index et l'endpoint gpf-research-private.
Il y a plusieurs étapes à la publication d’un index. Elles sont détaillées ci-dessous.
Création du flux de chargement de la livraison
Requête POST :
{{URL}}/datastores/{{DATASTORE_ID}}/uploads
Body :
{
"type": "INDEX",
"description": "TESTAUTOINDEXCUSTOM",
"name": "TESTAUTOINDEXCUSTOM",
"type_infos" : {
"is_search_layer" : true
},
"srs": "EPSG:4326"
}
Cette requête nous fournit en retour un UPLOAD_ID, qui sera nécessaire par la suite. C'est à cette étape qu'est défini le flag is_search_layer.
Tous les paramètres sauf type sont à modifier.
Versement de fichier dans le flux de chargement
Il faut ensuite ajouter les fichiers à la livraison. On choisit de verser ici un fichier en format CSV. Nous aurons alors deux appels, l’un pour verser le fichier CSVT dans le flux et un autre pour le fichier CSV.
Requête pour le fichier CSVT :
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/uploads/{{UPLOAD_ID}}/data
Body (de type Multipart form) :
[
{"key":"file","type":"file","value":[".../example_wkt.csvt"],
{"key":"path","value":"pathAutoTest","type":"text"}
]
Ici, les valeurs de file et path sont à modifier.
Requête pour le fichier CSV :
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/uploads/{{UPLOAD_ID}}/data
Body (de type Multipart form) :
[
{"key":"file","type":"file","value":[".../example_wkt.csv"],
{"key":"path","value":"pathAutoTest","type":"text"}
]
Ici, les valeurs de file et path sont à modifier.
Il doit avoir autant de fichiers CSV que de fichiers CSVT dans la livraison.
Intégration des fichiers
Une livraison peut être clôturée avec seulement une paire CVST/CSV. Vous pouvez aussi continuer à charger d’autres paires de fichiers CSVT/CSV du même nom, ils seront traités dans le même index.
A la fin du versement des fichiers dans le flux de chargement, le flux doit être fermé afin de clôturer la livraison :
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/uploads/{{UPLOAD_ID}}/close
Une vérification va automatiquement être lancée pour vérifier la cohérence des fichiers. Il est possible de suivre le résultat de la vérification avec cette route :
GET :
{{URL}}/datastores/{{DATASTORE_ID}}/uploads/{{UPLOAD_ID}}
Lorsque la vérification devient passed, il est possible de passer à la suite de la création de l'index.
Pour accéder aux logs de la vérification (en cas d'erreur par exemple) :
GET :
{{URL}}/datastores/{{DATASTORE_ID}}/checks/executions/{{CHECK_PROCESSING_ID}}/logs
Traitements dans la Géoplateforme
Le traitement (ou processing au sens API Entrepôt) est l'étape de création d'une donnée stockée (stored data) dans le storage de type OPENSEARCH. C’est-à-dire que toutes les lignes des fichiers CSV ou JSON vont être transformées en autant de document de recherche dans un index custom.
Création du processing
On va commencer le processing en créant un traitement index2index.
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/processings/executions
Body :
{
"processing": "c3297784-71e6-4417-864b-f62514768b87",
"inputs": {
"upload": [
"{upload}"
]
},
"output": {
"stored_data": {
"name" : "index",
"storage_type" : "OPENSEARCH",
"storage_tags": []
}
}
}
Cette requête donne un execution_id et un stored_data_id qu'il faut conserver pour la suite.
Lancement et exécution du processing
Il faut ensuite lancer le traitement avec la requête suivante :
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/processings/executions/{{EXECUTION_ID}}/launch
Comme pour la livraison, on peut suivre le statut du traitement avec la requête suivante :
GET :
{{URL}}/datastores/{{DATASTORE_ID}}/processings/executions/{{EXECUTION_ID}}
Il est possible de suivre les logs du traitement :
{{URL}}/datastores/{{DATASTORE_ID}}/processings/executions/{{EXECUTION_ID}}/logs
A la fin de l'exécution du process, si le statut est en SUCCESS, il est possible de vérifier la donnée stockée générée :
GET :
{{URL}}/datastores/{{DATASTORE_ID}}/stored_data/{{STORED_DATA_ID}}
Configuration
Cette étape permet de configurer l’index custom. Pour cela, on suit les mêmes principes que pour les étapes précédentes, on va « créer » la configuration.
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/configurations
Body :
{
"type":"SEARCH",
"name":"layer AUTO TEST INDEX20",
"layer_name":"layerAUTOTEST_INDEX20",
"type_infos":{
"title":"title",
"abstract":"abstract",
"keywords":[
"AUTO",
"TEST"
],
"bbox":{
"west":0,
"south":0,
"north":90,
"east":90
},
"used_data":[
{
"stored_data":"{{STORED_DATA_ID}}"
}
]
},
"metadata":[
],
"attribution":{
"title":"newAttributionTitle",
"url":"https://www.google.com/",
"logo":{
"format":"image/jpeg",
"url":"https://www.google.com/",
"width":90,
"height":90
}
}
}
Il faut récupérer le configuration_id reçu en retour de la requête.
Ici, tous les champs sauf type sont à modifier.
Publication
Enfin pour que l’index custom soit visible, il faut publier l’offre créée. Pour cette étape, on va donc créer l’offering de l’index.
POST :
{{URL}}/datastores/{{DATASTORE_ID}}/configurations/{{CONFIGURATION_ID}}/offerings
Body :
{
"visibility": "PRIVATE",
"endpoint": "{{ENDPOINT_ID}}",
"open": true
}
Le champ open permet de déterminer le niveau de visibilité de l'index custom :
- Pour « open=true », l'index custom sera accessible à tous une fois l'utilisateur connecté sur la Géoplateforme (avec un compte Géoplateforme ou une autre clé).
- Pour « open=false », l'index custom ne sera accessible qu'aux personnes ayant reçu une permission du gérant de l'index. Pour en savoir plus sur la création de permission et la gestion des cléshttps://geoplateforme.github.io/tutoriels/controle-des-acces/.
La visibility est précisée textuellement avec : PUBLIC ou PRIVATE.
L’endpoint est à préciser par le producteur de l’index.
Pour surveiller le statut de notre publication :
GET :
{{URL}}/datastores/{{DATASTORE_ID}}/configurations/{{CONFIGURATION_ID}}/offerings
Une fois l'offre en PUBLISHED, l’index custom est maintenant créé et intégré à la Géoplateforme. Des recherches peuvent être effectuées dessus via le service de recherche.
Titre
2.2.2 Mettre à jour un index custom
Ajout de documents sur l’index custom
Pour ajouter des documents à un index, il faut livrer les nouveaux documents en respectant le schéma défini précédemment pour l'index. Il faut ensuite refaire un traitement avec la nouvelle livraison en précisant l'id de la donnée stockée de l'index à mettre à jour.
POST :
/datastores/{datastore}/processings/executions
Body :
{
"processing": "c3297784-71e6-4417-864b-f62514768b87",
"inputs": {
"upload": [
"{upload}"
],
"stored_data": []
},
"output": {
"stored_data": {
"id" : "{stored_data}"
}
}
}
Une fois le traitement terminé, l'index est à jour et les nouveaux documents peuvent être recherchés.
Suppression ou modification de documents sur l'index
Pour supprimer ou modifier des documents d'un index, il faut dépublier l'index actuel et relivrer intégralement les documents de l'index (documents conservés et modifiés).
Il faut bien vérifier avant de dépublier l'index que vous possédez bien tous les documents de l'index afin de les relivrer par la suite. Après la livraison, il faut reprendre les étapes de traitements et de publication comme précédemment pour rendre de nouveau accessible l'index.
Titre
2.2.3 Effectuer une recherche dans un index custom
Lister les index custom
Pour effectuer une recherche sur un index custom, il faudra se connecter au préalable avec un compte Géoplateforme ou une clé défini précédemment.
Il est possible de lister les différents index custom qui nous sont disponibles avec cette route (toutes les index custom à open=true et les open=false où vous avez la permission) :
GET :
{{URL_SEARCH}}/private/api/indexes/indexes
Le champ index obtenu pour chaque index est à utiliser par la suite pour rechercher dans celui-ci. Il est défini selon le layer_name lors de la configuration dans l'entrepôt
Ensuite, la recherche dans les index custom fonctionne différemment selon la définition du Search Layer de l'index custom.
Index custom Search Layer
Il y a deux fonctionnements dans une recherche custom, qui dépendent du schéma des données importées et de la balise « is_search_layer ».
Si l‘index custom a un schéma compatible et porte un paramètre « is_search_layer :true », alors la recherche s’effectue de la même façon qu’une recherche standard. Néanmoins les requêtes de consultation par l’offre et consultation par l’ID ne fonctionnent pas.
La seule différence est l'URL de base qui prend /private/ :
{URL}/private/recherche/api/indexes/{index}
Index custom classique
Si l’index custom n’a pas un schéma compatible et porte le paramètre « is_search_layer :false », alors les champs de recherche sont ceux définis dans le schéma importé en parallèle du fichier de données (fichiers CSVT ou schema.json).
Les seules requêtes possibles sont la recherche POST de base et l'autocomplétion de titre. Ces deux requêtes fonctionnent comme pour l'index standard.
Pour la requête POST, les champs qui peuvent être recherchés correspondent à ceux définis dans le Get Capabilities de l'index.
Pour l'autocomplétion de titre, les champs qui peuvent être recherchés sont seulement ceux de type string.
Titre
3. Documentation swagger
Vous pouvez consulter la documentation Swagger de l’API REST à l’url suivante : https://data.geopf.fr/recherche/swagger-ui/index.html
Grâce à l’interface web de la documentation Swagger, vous pourrez facilement :
- consulter la liste des requêtes de recherche possible
- tester des appels à l’API en faisant varier les différents paramètres
- consulter les requêtes envoyées pour ces paramètres
- consulter des exemples de réponses retournées au format json
- visualiser les schémas de données des réponses aux requêtes
Concernant les réponses aux requêtes, la partie « schemas » illustre les éléments renvoyés et leur format.

L’encart « description » décrit l’action de la réponse.
Cette information est aussi présente dans chaque requête, dans la partie « Responses » > « schema » :

Titre
4. Bascule du service recherche de la GPF
Présentation
Le service de recherche permet d’effectuer des recherches sur les données. Les recherches peuvent fonctionner avec plusieurs options (recherche approximative, autocomplétion, etc).
Différences entre les services de recherche Géoportail et Géoplateforme
Bien que le principe de recherche reste le même, le fonctionnement du service de recherche de la Géoplateforme change complètement de celui proposé par le Géoportail.
Le nouveau service de recherche est scindé en deux :
- Une recherche standard qui s’effectue sur l’index standard « geoplateforme ».
- Elle permet d’obtenir des informations pour tout type d’offre entreposée de base dans la Géoplateforme. Toutes les données des grands producteurs (IGN puis CEREMA, SHOM, MNHN, etc) pourront être recherchées à travers ce service.
- URL d’accès (GetCapabilities) : https://data.geopf.fr/recherche/api/indexes
- Une recherche custom qui fonctionne sur des données importées.
- En plus de l'index standard, il est possible de créer ses propres index de recherche : ce sont les index custom. Ces index regroupent toutes les offres qui n’existent pas dans l’entrepôt de base de la Géoplateforme, mais qui ont été importées et publiées par des producteurs extérieurs.
- URL d’accès (GetCapabilities) : https://data.geopf.fr/private/recherche/api/indexes
Plusieurs différences à noter :
- Changements d’URL :
- Comme pour les autres géoservices, l’URL d’accès change, les URL définitives à prendre en compte sont celles ci-dessus.
- Par exemple au lieu de https://wxs.ign.fr/CLEF/look4/user/ , on aura https://data.geopf.fr/recherche/api/indexes
- L'appel au nouveau service se fait dans l’esprit Opendata de la Géoplateforme c’est à dire sans clé ou contrôle d’accès. Seuls l’accès de certains index custom (importés) pourront être restreints par leurs producteurs. L’accès à l’index standard de la Géoplateforme est complètement ouvert.
- Le service Look4 permettait la découverte (discover) et la recherche (search). La recherche pouvait s’effectuer sur plusieurs index. Aujourd’hui le service de recherche s’effectue sur un seul index. La découverte est directement intégrée au service de recherche.
- Auparavant, la requête devait indiquer une méthode de recherche en paramètre (prefix ou fuzzy). Aujourd’hui les méthodes de recherches sont directement indiquées dans le corps de la requête. Par exemple pour une requête qui permet la suggestion/l’autocomplétion du texte recherché, au lieu de https://wxs.ign.fr/essentiels/look4/user/search?indices=locating&method=fuzzy&match%5Bfulltext%5D= rout%20de%20communiation , on aura https://data.geopf.fr/recherche/api/indexes/geoplateforme/suggest?text=rout%20de%20communiation
- Auparavant, on pouvait filtrer les résultats en sortie (avec le paramètre filter), ce n’est plus le cas aujourd’hui.
- Auparavant, pour effectuer une recherche sur tous les champs, il fallait indiquer match =fulltext. Aujourd’hui la recherche sur tous les champs est par défaut.
Lien vers la documentation du nouveau service recherche